

Home
Операционна система
Entering Data in SPSS Statistics
Entering Data in SPSS Statistics
SPSS Statistics
Entering Variables
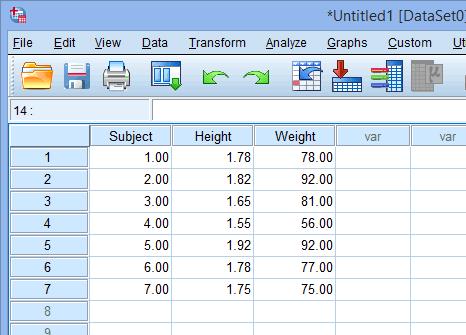
If you do not have repeated measures, SPSS Statistics treats each column as a separate variable. Thus, each variable goes in a separate column. For example, if we had measured the height and weight of a group of individuals, the data in SPSS Statistics would look like the following:
Published with written permission from SPSS Statistics, IBM Corporation.
The
Subject
column has been added so that it is clear that each individual is placed on a separate row. However, SPSS Statistics does not need you to enter this column, and it is mostly for you to be able to better visualize your data. So, even if we ignored the
Subject
column, we can see that one individual was 1.55 m tall and weighed 56 kg, looking at the
Height
and
Weight
columns, respectively. How to label variable columns is in our
Working with Variables
guide. To add more variables, simply add more columns - one column per variable. The only variation to this is discussed
later
in this guide when we have to enter repeated measures.
SPSS Statistics
Defining Separate Groups
HOW TO ENTER SURVEY DATA FROM RESEARCH TOOL/QUESTIONNAIRE INTO MS EXCEL I CHI-SQUARE IN SPSS I: https://t.co/FG0KeFE4YQ via @YouTube
— INFOKREEK Fri Jun 08 17:27:09 +0000 2018
Separate groups are more commonly called between-subjects factors or independent groups. They are groups where the individuals in each group are unique (i.e., no person is in more than one group). In this sense, you could call the groups "mutually-exclusive". A common example is
when differentiating between gender. You want to label some of your individuals as female and others as male. To identify which subjects were males and which were females, you need to create a "grouping variable" in SPSS Statistics. This is a separate column that includes information on which group a subject belongs to. We do this by labelling our groups numerically. For example, we label "males" as "1
" and "females" as "
2
". By using the
value
attribute we can label these numbers as representing males and females, respectively. An example is shown below:
Published with written permission from SPSS Statistics, IBM Corporation.
Looking at the columns on the left we can see that we have created a "grouping variable" called "Gender" that has two categories: "
1
" and "
2
". Because we labelled the numbers using the value attribute we can use the Value Label Button to switch to the text version of the "grouping variable" categories. In this example, we can see that "1" and "2" are replaced by "
Male
" and "
Female
", respectively. How to do this is explained in our guide on
Working with Variables
. You do not need to add text labels SPSS Statistics will work fine without them but it can provide extra clarity when analysing your data (especially as text labels are often used in the output instead of the numbers this helps greatly). We can see in this example that the first three subjects were males and the last four subjects were females. What if you have more than two categories of your "grouping variable"? Simple, just add more numbers with, we recommend, corresponding text labels.
Popular Articles/span>


